Senin, 15 Juli 2013
Selasa, 09 Juli 2013
Senin, 08 Juli 2013
Akhirnya aku menangis
Saya gak tau kenapa,
Membaca whatsappnya membuat saya menangis.
Saya tak bisa menggambarkan kenapa atau bagaimana.
Saya senang, sedih bercampuraduk semua.
Walau saya sering munafik didepan orang.
Sebenarnya diam-diam saya merindukannya.
Tetap mengaguminya.
Saya tak tahu mengapa saya menangis saat ini...
Perasaan apa yang ada dihati data
Saya tak bisa menjelaskannya.
Saya hanya ingin menangis
Membaca whatsappnya membuat saya menangis.
Saya tak bisa menggambarkan kenapa atau bagaimana.
Saya senang, sedih bercampuraduk semua.
Walau saya sering munafik didepan orang.
Sebenarnya diam-diam saya merindukannya.
Tetap mengaguminya.
Saya tak tahu mengapa saya menangis saat ini...
Perasaan apa yang ada dihati data
Saya tak bisa menjelaskannya.
Saya hanya ingin menangis

Rasanya seneng banget waktu diangkot jalan ke gelar jepang UI. Tiba-tiba handphone ada banyak whatsapp, bukan karena whatsapp yang banyak. Senang bukan kepalangnya adalah sewaktu dapet whatsapp dari seseorang yang benar-benar kita rindu. Meskipun malu ketawa-ketiwi sendiri waktu duduk di "bangku artis" diangkot, itulohh bangku cadangan yang tengah2 dekat pintu angkot. Tapi rasanya seneng banget sampai pen gen nangis rasanya. Seneng banget!
Mengingat "masih" dengan rasa yang terdahulu. Semuanya gak bisa diungkapkan kata-kata. Saya senang sekali hari ini. Walaupun saya gak tau makna dibalik semua ini, saya senang sekali. Berterimakasih sekali untuk anda hei seseorang yang masih ada dihati Dan pikiran saya. Atas whatsapp anda. Meski tak tau harus menjawab apa, saya bahagia sekali...
07/07/2013. Ay
Selasa, 02 Juli 2013
PARALLEL COMPUTATION
A. Parallelism Concept
Komputasi paralel merupakan salah satu teknik komputasi, dimana
proses komputasinya dilakukan oleh beberapa resources (
komputer ) yang independen, secara bersamaan. Komputasi paralel biasanya
diperlukan pada saat terjadinya pengolahan data dalam jumlah besar ( di
industri keuangan, bioinformatika, dll ) atau dalam memenuhi proses komputasi
yang sangat banyak. Selanjutnya, komputasi paralel ini juga dapat ditemui dalam
kasus kalkulasi numerik dalam penyelesaian persamaan matematis di bidang fisika
( fisika komputasi ), kimia ( kimia komputasi ), dll. Dalam menyelesaikan suatu
masalah, komputasi paralel memerlukan infrastruktur mesin paralel yang terdiri
dari banyak komputer yang dihubungkan dengan jaringan dan mampu bekerja secara
paralel.
Untuk itu diperlukan aneka perangkat lunak pendukung yang biasa
disebut sebagai middleware yang berperan untuk mengatur distribusi pekerjaan
antar node dalam satu mesin paralel. Selanjutnya pemakai harus membuat
pemrograman paralel untuk merealisasikan komputasi. Tidak berarti dengan mesin
paralel semua program yang dijalankan diatasnya otomatis akan diolah secara
paralel. Pemrograman paralel adalah teknik pemrograman komputer yang
memungkinkan eksekusi perintah / operasi secara bersamaan ( komputasi paralel
), baik dalam komputer dengan satu ( prosesor tunggal ) ataupun banyak (
prosesor ganda dengan mesin paralel ) CPU. Bila komputer yang digunakan secara
bersamaan tersebut dilakukan oleh komputer-komputer terpisah yang terhubung
dalam suatu jaringan komputer lebih sering istilah yang digunakan adalah sistem
terdistribusi ( distributed computing ). Tujuan utama dari pemrograman paralel
adalah untuk meningkatkan performa komputasi. Semakin banyak hal yang bisa
dilakukan secara bersamaan ( dalam waktu yang sama ), semakin banyak pekerjaan
yang bisa diselesaikan.
Analogi yang paling gampang adalah, bila anda dapat merebus air
sambil memotong-motong bawang saat anda akan memasak, waktu yang anda butuhkan
akan lebih sedikit dibandingkan bila anda mengerjakan hal tersebut secara
berurutan ( serial ). Atau waktu yang anda butuhkan memotong bawang akan lebih
sedikit jika anda kerjakan berdua. Performa dalam pemrograman paralel diukur
dari berapa banyak peningkatan kecepatan ( speed up ) yang diperoleh dalam
menggunakan tehnik paralel. Secara informal, bila anda memotong bawang
sendirian membutuhkan waktu 1 jam dan dengan bantuan teman, berdua anda bisa
melakukannya dalam 1/2 jam maka anda memperoleh peningkatan kecepatan sebanyak
2 kali.
B. Distributed
Processing
Pemrosesan paralel adalah pendekatan komputasi untuk meningkatkan tingkat di
mana satu set data diolah dengan pengolahan bagian yang berbeda dari data pada
waktu yang sama secara simultan atau bersamaan pada sebuah komputer dan
berfungsi memecah beban besar menjadi beberapa beban kecil untuk mempercepat
proses penyelesaian masalah.
Didistribusikan
pengolahan paralel menggunakan pemrosesan paralel pada beberapa mesin. Salah
satu contoh dari hal ini adalah bagaimana beberapa komunitas memungkinkan
pengguna untuk mendaftar dan mendedikasikan komputer mereka sendiri untuk
memproses beberapa data set yang diberikan kepada mereka oleh server. Ketika
ribuan pengguna mendaftar untuk ini, banyak data dapat diproses dalam jumlah yang
sangat singkat.
Tipe
lain dari komputasi paralel yang kadang-kadang disebut
"didistribusikan" adalah gagasan dari sebuah komputer paralel
cluster. Sebuah cluster akan banyak CPU terhubung melalui kecepatan tinggi
koneksi ethernet ke hub sentral (Server) yang memberi masing-masing beberapa
pekerjaan yang harus dilakukan. Metode cluster mirip dengan metode yang
dijelaskan dalam paragraf di atas, kecuali bahwa semua CPU secara langsung
terhubung ke server, dan satu-satunya tujuan mereka adalah untuk melakukan
perhitungan yang diberikan kepada mereka.
Parallel distributed computing dapat dibentuk dari :
-
Ada : digunakan konsep pertemuan yang menggabungkan fitur RPC dan monitor.
-
PVM (Parallel Virtual Machine) untuk mendukung workstation clusters
-
MPI (Message-Passing Interface) programming GUI untuk parallel computers.
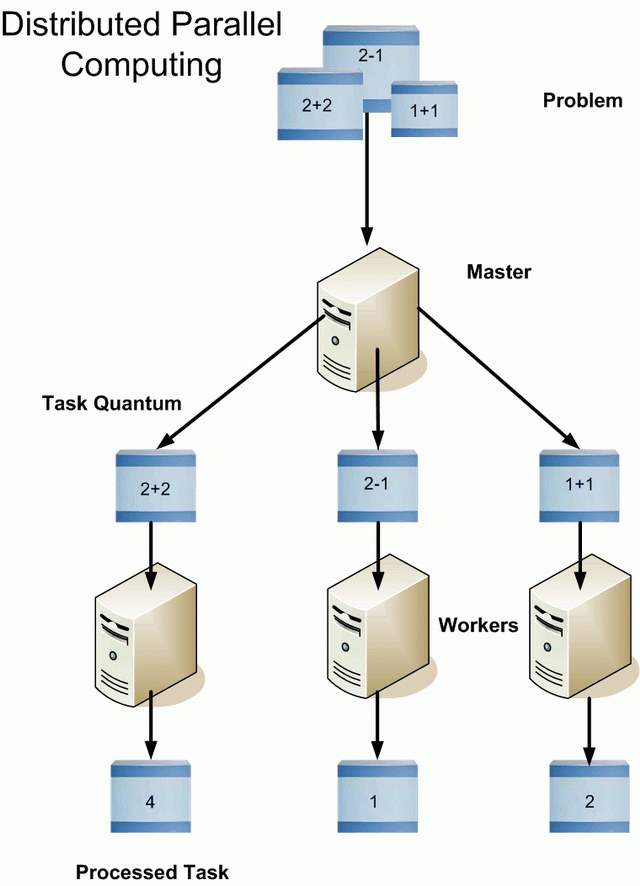
C. Architectural Parallel Computer
SISD
Yang merupakan singkatan dari Single Instruction, Single Data adalah satu-satunya yang menggunakan arsitektur Von Neumann. Ini dikarenakan pada model ini hanya digunakan 1 processor saja. Oleh karena itu model ini bisa dikatakan sebagai model untuk komputasi tunggal. Sedangkan ketiga model lainnya merupakan komputasi paralel yang menggunakan beberapa processor. Beberapa contoh komputer yang menggunakan model SISD adalah UNIVAC1, IBM 360, CDC 7600, Cray 1 dan PDP 1.
Yang merupakan singkatan dari Single Instruction, Single Data adalah satu-satunya yang menggunakan arsitektur Von Neumann. Ini dikarenakan pada model ini hanya digunakan 1 processor saja. Oleh karena itu model ini bisa dikatakan sebagai model untuk komputasi tunggal. Sedangkan ketiga model lainnya merupakan komputasi paralel yang menggunakan beberapa processor. Beberapa contoh komputer yang menggunakan model SISD adalah UNIVAC1, IBM 360, CDC 7600, Cray 1 dan PDP 1.
SIMD
Yang merupakan singkatan dari Single Instruction, Multiple Data. SIMD menggunakan banyak processor dengan instruksi yang sama, namun setiap processor mengolah data yang berbeda. Sebagai contoh kita ingin mencari angka 27 pada deretan angka yang terdiri dari 100 angka, dan kita menggunakan 5 processor. Pada setiap processor kita menggunakan algoritma atau perintah yang sama, namun data yang diproses berbeda. Misalnya processor 1 mengolah data dari deretan / urutan pertama hingga urutan ke 20, processor 2 mengolah data dari urutan 21 sampai urutan 40, begitu pun untuk processor-processor yang lain. Beberapa contoh komputer yang menggunakan model SIMD adalah ILLIAC IV, MasPar, Cray X-MP, Cray Y-MP, Thingking Machine CM-2 dan Cell Processor (GPU).
Yang merupakan singkatan dari Single Instruction, Multiple Data. SIMD menggunakan banyak processor dengan instruksi yang sama, namun setiap processor mengolah data yang berbeda. Sebagai contoh kita ingin mencari angka 27 pada deretan angka yang terdiri dari 100 angka, dan kita menggunakan 5 processor. Pada setiap processor kita menggunakan algoritma atau perintah yang sama, namun data yang diproses berbeda. Misalnya processor 1 mengolah data dari deretan / urutan pertama hingga urutan ke 20, processor 2 mengolah data dari urutan 21 sampai urutan 40, begitu pun untuk processor-processor yang lain. Beberapa contoh komputer yang menggunakan model SIMD adalah ILLIAC IV, MasPar, Cray X-MP, Cray Y-MP, Thingking Machine CM-2 dan Cell Processor (GPU).
MISD
Yang merupakan singkatan dari Multiple Instruction, Single Data. MISD menggunakan banyak processor dengan setiap processor menggunakan instruksi yang berbeda namun mengolah data yang sama. Hal ini merupakan kebalikan dari model SIMD. Untuk contoh, kita bisa menggunakan kasus yang sama pada contoh model SIMD namun cara penyelesaian yang berbeda. Pada MISD jika pada komputer pertama, kedua, ketiga, keempat dan kelima sama-sama mengolah data dari urutan 1-100, namun algoritma yang digunakan untuk teknik pencariannya berbeda di setiap processor. Sampai saat ini belum ada komputer yang menggunakan model MISD.
Yang merupakan singkatan dari Multiple Instruction, Single Data. MISD menggunakan banyak processor dengan setiap processor menggunakan instruksi yang berbeda namun mengolah data yang sama. Hal ini merupakan kebalikan dari model SIMD. Untuk contoh, kita bisa menggunakan kasus yang sama pada contoh model SIMD namun cara penyelesaian yang berbeda. Pada MISD jika pada komputer pertama, kedua, ketiga, keempat dan kelima sama-sama mengolah data dari urutan 1-100, namun algoritma yang digunakan untuk teknik pencariannya berbeda di setiap processor. Sampai saat ini belum ada komputer yang menggunakan model MISD.
MIMD
Yang merupakan singkatan dari Multiple Instruction, Multiple Data. MIMD menggunakan banyak processor dengan setiap processor memiliki instruksi yang berbeda dan mengolah data yang berbeda. Namun banyak komputer yang menggunakan model MIMD juga memasukkan komponen untuk model SIMD. Beberapa komputer yang menggunakan model MIMD adalah IBM POWER5, HP/Compaq AlphaServer, Intel IA32, AMD Opteron, Cray XT3 dan IBM BG/L.
Yang merupakan singkatan dari Multiple Instruction, Multiple Data. MIMD menggunakan banyak processor dengan setiap processor memiliki instruksi yang berbeda dan mengolah data yang berbeda. Namun banyak komputer yang menggunakan model MIMD juga memasukkan komponen untuk model SIMD. Beberapa komputer yang menggunakan model MIMD adalah IBM POWER5, HP/Compaq AlphaServer, Intel IA32, AMD Opteron, Cray XT3 dan IBM BG/L.
Singkatnya untuk perbedaan
antara komputasi tunggal dengan komputasi paralel, bisa digambarkan pada gambar
di bawah ini:

Gambar 1 Penyelesaian
Sebuah Masalah pada Komputasi Tunggal

Gambar
2 Penyelesaian Sebuah Masalah pada Komputasi Paralel
Dari perbedaan
kedua gambar di atas, kita dapat menyimpulkan bahwa kinerja komputasi paralel
lebih efektif dan dapat menghemat waktu untuk pemrosesan data yang banyak
daripada komputasi tunggal.
Dari
penjelasan-penjelasan di atas, kita bisa mendapatkan jawaban mengapa dan kapan
kita perlu menggunakan komputasi paralel. Jawabannya adalah karena komputasi
paralel jauh lebih menghemat waktu dan sangat efektif ketika kita harus
mengolah data dalam jumlah yang besar. Namun keefektifan akan hilang ketika
kita hanya mengolah data dalam jumlah yang kecil, karena data dengan jumlah
kecil atau sedikit lebih efektif jika kita menggunakan komputasi tunggal.
D.
Pengantar Thread Programming
Dalam pemrograman komputer, sebuah thread adalah informasi terkait
dengan penggunaan sebuah program tunggal yang dapat menangani beberapa pengguna
secara bersamaan. Dari program point-of-view, sebuah thread adalah informasi
yang dibutuhkan untuk melayani satu pengguna individu atau permintaan layanan
tertentu. Jika beberapa pengguna menggunakan program atau permintaan bersamaan
dari program lain yang sedang terjadi, thread yang dibuat dan dipelihara untuk
masing-masing proses. Thread memungkinkan program untuk mengetahui user sedang
masuk didalam program secara bergantian dan akan kembali masuk atas nama
pengguna yang berbeda. Salah satu informasi thread disimpan dengan cara
menyimpannya di daerah data khusus dan menempatkan alamat dari daerah data
dalam register. Sistem operasi selalu menyimpan isi register saat program
interrupted dan restores ketika memberikan program kontrol lagi.
Sebagian besar komputer hanya dapat mengeksekusi satu instruksi
program pada satu waktu, tetapi karena mereka beroperasi begitu cepat, mereka
muncul untuk menjalankan berbagai program dan melayani banyak pengguna secara
bersamaan. Sistem operasi komputer memberikan setiap program
"giliran" pada prosesnya, maka itu memerlukan untuk menunggu
sementara program lain mendapat giliran. Masing-masing program dipandang oleh
sistem operasi sebagai suatu tugas dimana sumber daya tertentu diidentifikasi
dan terus berlangsung. Sistem operasi mengelola setiap program aplikasi dalam
sistem PC (spreadsheet, pengolah kata, browser Web) sebagai tugas terpisah dan
memungkinkan melihat dan mengontrol item pada daftar tugas. Jika program
memulai permintaan I / O, seperti membaca file atau menulis ke printer, itu
menciptakan thread. Data disimpan sebagai bagian dari thread yang memungkinkan
program yang akan masuk kembali di tempat yang tepat pada saat operasi I / O
selesai. Sementara itu, penggunaan bersamaan dari program diselenggarakan pada
thread lainnya. Sebagian besar sistem operasi saat ini menyediakan dukungan
untuk kedua multitasking dan multithreading. Mereka juga memungkinkan
multithreading dalam proses program agar sistem tersebut disimpan dan
menciptakan proses baru untuk setiap thread.
Static Threading
Teknik ini biasa digunakan untuk komputer dengan chip
multiprocessors dan jenis komputer shared-memory lainnya. Teknik ini
memungkinkan thread berbagi memori yang tersedia, menggunakan program counter
dan mengeksekusi program secara independen. Sistem operasi menempatkan satu
thread pada prosesor dan menukarnya dengan thread lain yang hendak menggunakan
prosesor itu.
Mekanisme ini terhitung lambat, karenanya disebut dengan static.
Selain itu teknik ini tidak mudah diterapkan dan rentan kesalahan. Alasannya,
pembagian pekerjaan yang dinamis di antara thread-thread menyebabkan load
balancing-nya cukup rumit. Untuk memudahkannya programmer harus menggunakan
protocol komunikasi yang kompleks untuk menerapkan scheduler load balancing.
Kondisi ini mendorong pemunculan concurrency platforms yang menyediakan layer
untuk mengkoordinasi, menjadwalkan, dan mengelola sumberdaya komputasi paralel.
Sebagian platform dibangun sebagai runtime libraries atau sebuah
bahasa pemrograman paralel lengkap dengan compiler dan pendukung runtime-nya.
Dynamic Multithreading
Teknik ini merupakan pengembangan dari teknik sebelumnya yang
bertujuan untuk kemudahan karena dengannya programmer tidak harus pusing dengan
protokol komunikasi, load balancing, dan kerumitan lain yang ada pada static
threading. Concurrency platform ini menyediakan scheduler yang melakukan load
balacing secara otomatis. Walaupun platformnya masih dalam pengembangan namun
secara umum mendukung dua fitur : nested parallelism dan parallel loops. Nested
parallelism memungkinkan sebuah subroutine di-spawned (ditelurkan dalam jumlah
banyak seperti telur katak) sehingga program utama tetap berjalan sementara
subroutine menghitung hasilnya. Sedangkan parallel loops seperti halnya fungsi
for namun memungkinkan iterasi loop dilakukan secara bersamaan.
E. Pengantar Massage Passing dan OpenMP
OpenMP (Open Multi-Processing) adalah sebuah antarmuka pemrograman aplikasi (API) yang mendukung
multi processing shared memory pemrograman di C, C++ dan Fortran pada
berbagai arsitektur, termasuk UNix dan Microsoft Windows platform. OpenMP
Terdiri dari satu set perintah kompiler, perpustakaan rutinitas, dan variabel
lingkungan yang mempengaruhi run-time. Banyak Aplikasi dibangun dengan model
hibrida pemrograman paralel dapat dijalankan pada komputer cluster dengan
menggunakan OpenMP dan Message Passing Interface (MPI), atau lebih transparan
dengan menggunakan ekstensi OpenMP non-shared memory systems.
Sejarah
OpenMP dimulai dari diterbitkannya API pertama untuk Fotran 1.0 pada Oktober
1997 oleh OpenMP Architecture Review Board (ARB). Oktober tahun berikutnya
OpenMP Architecture Review Board (ARB) merilis standart C / C++. Pada tahun
2000 mengeluarkan versi 2.0 untuk fotran dan poda tahun 2002 dirilis versi 2.0
untuk C / C++. Pada tahun 2005 dirilis versi 2.5 yang merupakan pengabungan
fotran, C, dan C++/ pada mei 2008 versi 3.0 yang terdapat didalmnya konsept
tasks dan task construct.
OpenMP
mengimplementasi multithreading. Bagian kode yang akan dijalankan secara
parallel ditandai sesuai dengan Preprocessor directif sehingga akan membuat
thread-thread sebelum dijalnkan. Setiap thread memiliki id yang di buat
menggunakan fungsi (omp_get_thread_num() pada C/C++ dan
OMP_GET_THREAD_NUM() pada Fortran). Secara default, setiap thread mengeksekusi
kode secara parallel dan independent. "Work-sharing constructs" dapat
dapat digunakan untuk membagi tugas antar thread sehingga setiap thread
menjalankan sesuai bagian alokasi kodenya. Fungsi OpenMP berada pada file header
yang berlabel “omp.h” di C / C++.
F. Pengantar Pemrograman CUDA GPU
Sebuah GPU
(Graphical Processing Unit) pada awalnya adalah sebuah prosesor
yang berfungsi khusus untuk melakukan rendering pada kartu grafik saja, tetapi
seiring dengan semakin meningkatnya kebutuhan rendering, terutama untuk
mendekati waktu proses yang realtime /sebagaimana kenyataan sesungguhnya, maka
meningkat pula kemampuan prosesor grafik tersebut. akselerasi peningkatan
teknologi GPU ini lebih cepat daripada peningkatan teknologi prosesor
sesungguhnya (CPU), dan pada akhirnya GPU menjadi General Purpose, yang artinya
tidak lagi hanya untuk melakukan rendering saja melainkan bisa untuk proses
komputasi secara umum.
penggunaan
Multi GPU dapat mempercepat waktu proses dalam mengeksekusi program karena
arsitekturnya yang natively parallel. Selain itu Peningkatan performa yang
terjadi tidak hanya berdasarkan kecepatan hardware GPU saja, tetapi faktor yang
lebih penting adalah cara membuat kode program yang benarbenar bisa efektif
berjalan pada Multi GPU.
CUDA merupakan teknologi anyar dari produsen kartu
grafis Nvidia, dan mungkin belum banyak digunakan orang secara umum. Kartu
grafis lebih banyak digunakan untuk menjalankan aplikasi game, namun dengan
teknologi CUDA ini kartu grafis dapat digunakan lebih optimal ketika
menjalankan sebuah software aplikasi. Fungsi kartu grafis Nvidia digunakan
untuk membantu Processor (CPU) dalam melakukan kalkulasi dalam proses data.
CUDA merupakan singkatan dari Compute Unified Device
Architecture,didefinisikan sebagai sebuah arsitektur komputer
parallel, dikembangkan oleh Nvidia. Teknologi ini dapat digunakan untuk
menjalankan proses pengolahan gambar, video, rendering 3D, dan lain sebagainya.
VGA – VGA dari Nvidia yang sudah menggunakan teknologi CUDA antara lain :
Nvidia GeForce GTX 280, GTX 260,9800 GX2, 9800 GTX+,9800 GTX,9800 GT,9600 GSO,
9600 GT,9500 GT,9400 GT,9400 mGPU,9300 mGPU,8800 Ultra,8800 GTX,8800 GTS,8800
GT,8800 GS,8600 GTS,8600 GT,8500 GT,8400 GS, 8300 mGPU, 8200 mGPU, 8100 mGPU,
dan seri sejenis untuk kelas mobile (VGA notebook).
Singkatnya,
CUDA dapat memberikan proses dengan pendekatan bahasa C, sehingga programmer
atau pengembang software dapat lebih cepat menyelesaikan perhitungan yang
komplek. Bukan hanya aplikasi seperti teknologi ilmu pengetahuan yang spesifik.
CUDA sekarang bisa dimanfaatkan untuk aplikasi multimedia. Misalnya
meng-edit film dan melakukan filter gambar. Sebagai contoh dengan aplikasi
multimedia, sudah mengunakan teknologi CUDA. Software TMPGenc 4.0 misalnya
membuat aplikasi editing dengan mengambil sebagian proces dari GPU dan CPU. VGA
yang dapat memanfaatkan CUDA hanya versi 8000 atau lebih tinggi.
Keuntungan
dengan CUDA sebenarnya tidak luput dari teknologi aplikasi yang ada. CUDA akan
mempercepat proses aplikasi tertentu, tetapi tidak semua aplikasi yang ada akan
lebih cepat walaupun sudah mengunakan fitur CUDA. Hal ini tergantung seberapa
cepat procesor yang digunakan, dan seberapa kuat sebuah GPU yang dipakai. Dan
bagian terpenting adalah aplikasi apa yang memang memanfaatkan penuh kemampuan
GPU dengan teknologi CUDA. Kedepan seperti pengembang software Adobe akan ikut
memanfaatkan fitur CUDA pada aplikasi mereka. Jawaban akhir adalah, untuk
memanfaatkan CUDA kembali melihat aplikasi software yang ada. Apakah software
yang ada memang mampu memanfaatkan CUDA dengan proses melalui GPU secara penuh.
Hal tersebut akan berguna untuk mempercepat selesainya proses pada sebuah
aplikasi. Dengan kecepatan proses GPU, aplikasi akan jauh lebih cepat.
Khususnya teknologi ilmu pengetahuan dengan ramalan cuaca, simulator
pertambangan atau perhitungan yang rumit dibidang keuangan. Sedangkan aplikasi
umum sepertinya masih harus menunggu.
SUMBER
Langganan:
Komentar (Atom)